선형 회귀와 다항 회귀를 공부하며 독립변수가 하나인 데이터들에 대해 살펴봤습니다.
이번 포스팅에서는 독립변수가 2개 이상인 다중 회귀에 대해 알아보겠습니다.
우선 fish_full.csv 첨부를 다운 받고 google drive에 복사해 보겠습니다.
복사 후 pandas를 활용해 dataframe을 만들어 봅시다.
이후 model 학습을 위해 numpy.array로 형태를 바꿔주겠습니다.
import pandas as pd
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/fish_full.csv')
fish_full = df.to_numpy()
fish_full[:5]
보시는 바와 같이 3개의 독립변수가 입력되어 있습니다.
각 column이 무엇을 뜻하는지 excel에서 csv파일을 열어 확인해보겠습니다.
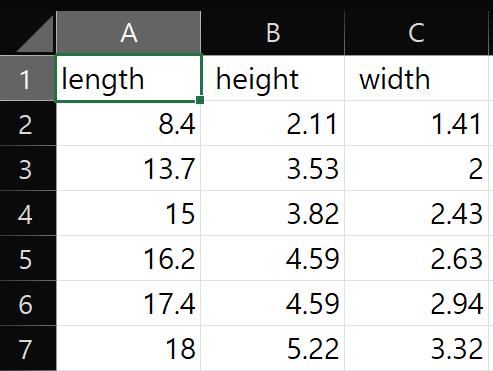
좌측부터 물고기의 길이, 높이, 넓이가 나와있는 데이터임을 알 수 있습니다.
이제 target_set이 될 물고기 무게를 정의해보겠습니다.
fish_weight = np.array(
[5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0,
110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0,
130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0,
197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0,
514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0,
820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0,
1000.0, 1000.0]
)
Train_set과 Test_set을 분리해보겠습니다.
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(fish_full, fish_weight, test_size = 0.2, random_state = 42)
이제 degree = 5인 poly data를 생성해보겠습니다.
from sklearn.preprocessing import PolynomialFeatures
poly_features = PolynomialFeatures(degree = 5, include_bias = False)
poly_features.fit(train_input)
train_poly = poly_features.transform(train_input)
test_poly = poly_features.transform(test_input)
train_poly가 제대로 생성되었는지 확인해보겠습니다.
우선 get_feature_name_out()을 통해 다항 특성들을 파악해보겠습니다.
poly_features.get_feature_names_out()
train_poly[0]
poly data들이 잘 만들어졌습니다. 그런데 숫자가 너무 큰 것으로 보아 과대적합의 냄새가 나는 것 같습니다.
이후 표준화를 통해 다듬어 보겠습니다.
우선 표준화 이전에 model을 학습시켜보고 score를 먼저 확인해보겠습니다.
필요하다면 표준화 과정을 거쳐주면 됩니다.
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(train_poly, train_target)
학습을 완료시켰습니다.
score를 확인해보겠습니다.
lr.score(train_poly, train_target)
-> 0.9999999999219743Train_set에 대한 점수는 매우 놉게 나온 것을 확인할 수 있습니다.
이제 Test_set에 대한 점수가 높게 나온다면 학습된 model은 잘 만들어진 model이라고 판단할 수 있습니다.
lr.score(test_poly, test_target)
-> -167.27004880370916Test_set의 score가 -167... 음수가 나왔습니다.
modelling을 잘못했다는 것을 알 수 있습니다.
degree = 5 로 설정했기 때문에 과대적합에 해당한다고 유추할 수 있습니다.
train_poly들의 값이 너무 크기 때문에 표준화 (평균 : 0, 표준편차 : 1)를 통해 data를 변경해보겠습니다.
즉 train_poly와 test_poly의 scale을 조정하는 것입니다.
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_poly)
train_scaled = ss.transform(train_poly)
test_scaled = ss.transform(test_poly)
릿지 회귀와 라쏘 회귀를 각각 적용해보겠습니다.
1. 릿지 회귀(제곱의 합)
# 릿지 회귀 적용
from sklearn.linear_model import Ridge
ridge = Ridge()
ridge.fit(train_scaled, train_target)
릿지 회귀에 대한 model 점수화를 해보겠습니다.
ridge.score(train_scaled, train_target)
-> 0.9896004835191297
ridge.score(test_scaled, test_target)
-> 0.9789200583251785
2. 라쏘 회귀(절대값의 합)
# 라쏘 회귀 적용
from sklearn.linear_model import Lasso
lasso = Lasso()
lasso.fit(train_scaled, train_target)
라쏘 회귀에 대한 model 점수화를 해보겠습니다.
lasso.score(train_scaled, train_target)
-> 0.9897812228260618
lasso.score(test_scaled, test_target)
-> 0.9800354016844837'데이터 사이언스 > 하계 AI 중급과정' 카테고리의 다른 글
| Ch 7. Logistic Regression (로지스틱 회귀) (0) | 2023.07.15 |
|---|---|
| Ch 6. Gradient descent (경사하강법) (0) | 2023.07.14 |
| Ch 4. Polynomial Regression (다항회귀) (0) | 2023.07.12 |
| Ch 3. Linear Regression(선형회귀) (0) | 2023.07.12 |
| Ch 2. 훈련 및 테스트 세트 (Train set, Test set) (0) | 2023.07.11 |



